Hier soir, lors de sa conférence de développeurs I/O, Google a présenté des nouveautés pour son moteur de recherche, son système d’exploitation Android, et divers services en ligne d’intelligence artificielle (AI). Voici les 10 principales annonces à retenir de cette conférence dominée, cette année encore, par l’intelligence artificielle générative et Gemini 1.5.
Gemini 1.5 Pro : une IA encore plus puissante
Sans surprise, Google a dévoilé des avancées significatives avec son modèle d’IA. Parmi ces nouveautés, Gemini 1.5 Pro se distingue par sa capacité à traiter de grandes quantités d’informations (tokens), offrant ainsi la possibilité de gérer des documents volumineux et de fournir des analyses détaillées.

Comparé à la précédente version, Gemini 1.5 Pro se démarque dans 87% des tests de référence, passant de 32 000 à 1 million tokens. Concrètement, cela lui permet d’analyser rapidement 1500 pages de texte ou 100 courriels. Google prévoit également d’étendre cette capacité à traiter des contenus plus complexes tels qu’une heure de contenu vidéo ou des bases de code de plus de 30 000 lignes.
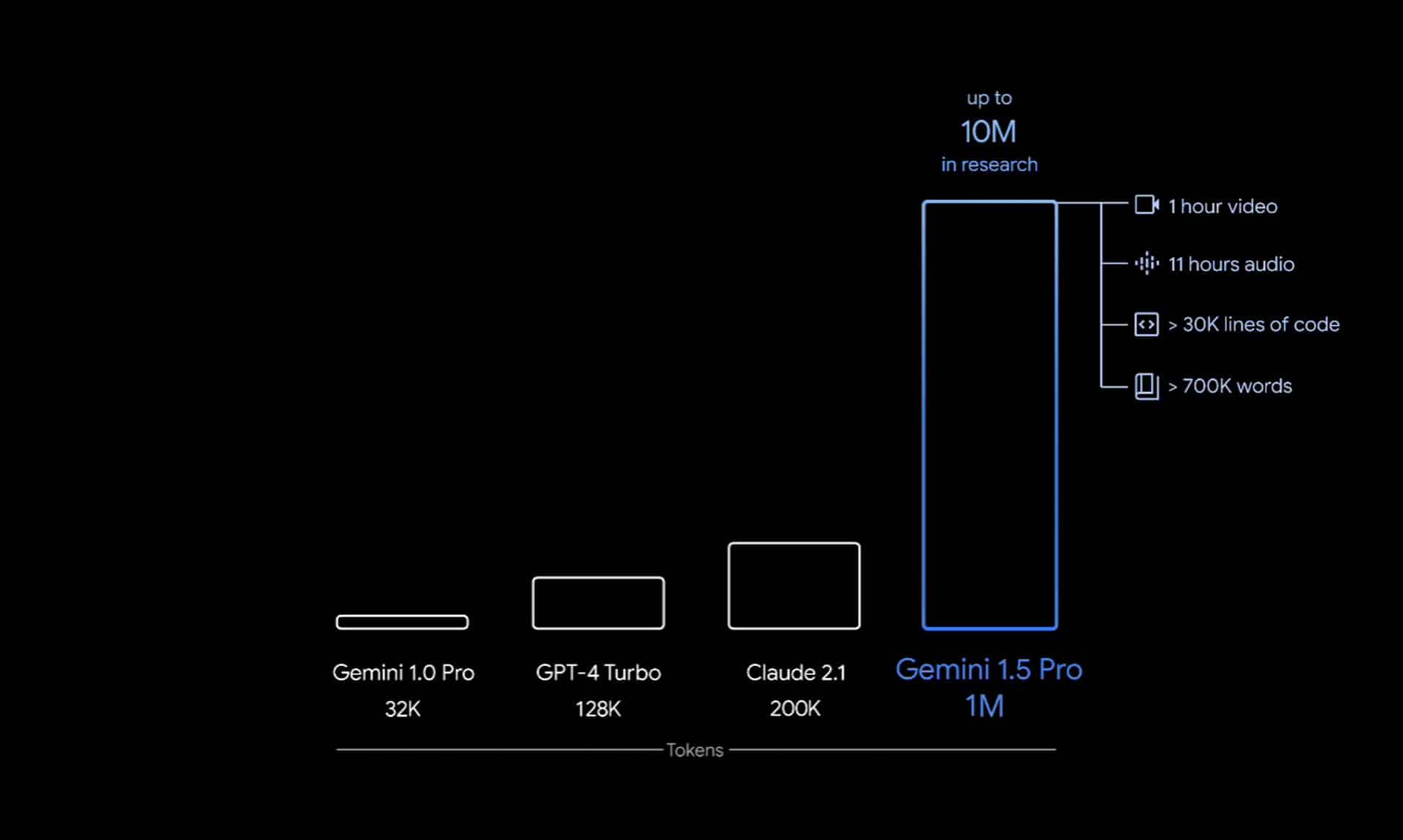
De plus, Gemini 1.5 Pro prend en charge l’analyse multimodale, incluant l’audio, ce qui permet une analyse transparente et complète des textes, images, vidéos et audio. Cette version multimodale offre des fonctionnalités avancées telles que la réponse à des requêtes basées sur des images ou du texte, utilisant une combinaison de ces contenus pour fournir des réponses plus riches.
Sans surprise, tout ça n’est pas gratuit et Google réserve Gemini Advanced et Gemini 1.5 Pro à ses abonnés. Cette technologie sera déployée dans plus de 150 pays, y compris en France, et prendra en charge plus de 35 langues.
Gemini débarque dans la recherche Google
Quinze mois après que Microsoft ait ajouté Copilot – basé sur GPT-4 d’OpenAI, ndlr – à son moteur Bing, Gemini va enfin être intégré au moteur de recherche de Google aux États-Unis. Le leader de la recherche sur le web prévoit d’étendre cette fonctionnalité à d’autres pays d’ici la fin de l’année. Cependant, l’expérience ne sera pas radicalement transformée car Gemini n’interviendra que pour certaines requêtes, lorsque le moteur estimera que son intervention est pertinente. C’est plutôt une bonne nouvelle.
… et sur nos smartphones sous Android
Le modèle d’IA sera également intégré au cœur du système d’exploitation Android pour smartphones. Gemini pourra être utilisé dans de nombreuses applications pour, par exemple, répondre à des questions, générer de courts textes ou créer des images.

Plusieurs incertitudes subsistent, en particulier concernant la manière de l’activer et l’avenir de Google Assistant. Si les démonstrations font usage du mot de réveil Gemini, on voit mal l’intérêt de faire cohabiter les deux assistants, celui traditionnellement activé par « OK Google » semblant désormais bien désuet.
On ne sait pas non plus si cette IA sera capable de converser de manière fluide à l’oral, comme ChatGPT Voice, ni combien de smartphones bénéficieront de cette nouvelle fonctionnalité. En effet, tous les anciens appareils Android ne recevront pas cette mise à jour, et tous les nouveaux modèles ne seront pas non plus dotés de Gemini dans l’immédiat. Google réservera-t-il la primeur de son IA à ses Pixels ? C’est fort probable.
Gemini 1.5 Flash : une version light
La firme californienne a également dévoilé une nouvelle version de son grand modèle de langage (LLM) appelée Gemini 1.5 Flash. Conçu « pour être rapide et efficace à grande échelle », c’est un modèle plus léger que Gemini 1.5 Pro dont l’objectif n’est pas d’être utilisable directement par le grand public, mais plutôt d’être intégré à certaines applications via l’API de Google. Ce LLM est optimisé pour les tâches à haut volume et haute fréquence, offrant ainsi une solution plus rentable pour les entreprises.

Project Astra : un assistant multimodal
Ce fut sans aucun doute la présentation la plus impressionnante de ce Google I/O. Avec Project Astra, le géant du web a présenté un assistant multimodal assez semblable au modèle GPT-4o d’OpenAI que nous évoquions hier, que nous qualifierons sans mal d’avancée majeure dans le domaine de l’IA car il préfigure à notre sens ce que sont appelés à devenir nos assistants vocaux tels que Google Assistant, Alexa ou Siri.

Développé par l’équipe de DeepMind, Project Astra est un assistant basé sur Gemini capable de fournir des réponses conversationnelles en temps réel à une grande variété de requêtes en s’appuyant aussi bien sur la voix que sur le texte, l’audio, les photos et vidéos. Cet assistant se distingue par sa capacité à identifier les objets, suggérer des noms, analyser du code et localiser des objets grâce à des indices visuels ou audio. Une approche qui rend les interactions avec l’IA plus intuitives et plus adaptées aux besoins des utilisateurs. Google a même fait la démonstration de son usage avec des lunettes de réalité augmentée. Regardez la vidéo ci-dessous, elle est assez incroyable !
Cependant, Google devra faire vite car son concurrent OpenAI a déjà bien avancé sur le sujet et offre des réponses vocales plus naturelles et moins monotones. La technologie du projet Astra sera intégrée à Gemini, améliorant ainsi ses fonctionnalités et offrant une expérience utilisateur encore plus enrichissante.
Gemini Nano : une version allégée et locale pour Chrome
Gemini Nano est une version allégée de Gemini, conçue pour fonctionner localement sur les appareils sans connexion au cloud, qui sera intégrée à la version 126 de Google Chrome pour les ordinateurs. L’intégration permettra aux utilisateurs de Chrome d’utiliser l’IA pour des tâches telles que la traduction, la transcription et la génération de texte, avec des temps de réponse rapides grâce au traitement local. Autre point à souligner, les développeurs pourront l’utiliser via une API pour l’intégrer à leurs sites web et applications, et proposer aux utilisateurs des fonctionnalités d’intelligence artificielle générative.

Imagen 3 : le meilleur générateur d’images ?
Google a également annoncé des avancées significatives dans la génération d’images par IA, visant à rivaliser avec des modèles populaires tels que DALL-E et MidJourney. La nouvelle version de l’outil son modèle, appelée Imagen 3, promet de produire des images encore plus réalistes et artistiques. Selon Mountain View, il s’agirait du meilleur générateur d’images à l’heure actuelle.
Imagen 3 utilise un modèle de diffusion avancé pour créer des visuels à partir de descriptions textuelles détaillées. L’IA fonctionne en affinant progressivement un motif initial aléatoire de points pour former une image cohérente et esthétiquement plaisante. Google a mis l’accent sur la qualité et la précision des images générées, espérant surpasser la concurrence en termes de détails et de réalisme.

Les IA génératives comme DALL-E et MidJourney ont déjà démontré leur capacité à créer des images impressionnantes à partir de simples descriptions textuelles, et sont largement utilisées dans divers domaines, notamment l’e-commerce, l’architecture et les jeux vidéo, pour produire rapidement des visuels de haute qualité. Google espère que ses améliorations dans Imagen 3 permettront aux utilisateurs d’obtenir des résultats encore plus raffinés, enrichissant ainsi les possibilités créatives offertes par l’IA.
Music AI Sandbox : la musique assistée par l’intelligence artificielle
Sur le plan musical, Google a présenté Music AI Sandbox. Conçu en partenariat avec YouTube, cet outil permet de générer des pistes musicales à partir d’une simple description textuelle ou de transformer le style d’une mélodie en quelques secondes. Douglas Eck, directeur de la recherche, a expliqué avoir collaboré avec des artistes et montré, à travers quelques vidéos, comment l’IA pouvait les aider à stimuler leur créativité.
Veo : un modèle de génération de vidéo
Le dernier moment fort de ce Google I/O fut sans aucun doute la présentation de Veo, un outil de création de vidéos. Très attendu dans ce domaine, Google semble avoir obtenu des résultats prometteurs. Veo peut générer des films en 1080p de plus d’une minute à partir de texte, d’images ou de vidéos. Il peut également intégrer des descriptions cinématographiques pour un rendu plus précis, incluant des vues aériennes ou des timelapses.
Cet outil est le résultat d’un travail de longue haleine et repose sur des modèles génératifs précédents tels qu’Imagen-Video, Phenaki, WALT, VideoPoet et Lumiere. Actuellement, Veo est accessible à quelques privilégiés via une inscription à Google Labs.

Trillium et Axion : de nouvelles puces pour l’IA
Sundar Pichai a également présenté une nouvelle unité de traitement de tenseur (TPU). La puce Trillium de 6ème génération offrira des performances de calcul 4,7 fois supérieures à celles de la TPU v5e. Elle est conçue pour alimenter les serveurs qui génèrent du texte et d’autres médias à partir de grands modèles de langage. Le processeur Trillium est par ailleurs 67 % plus économe en énergie que sa version précédente et sera disponible pour les clients cloud d’ici la fin de l’année.
Enfin, le PDG de Google a levé le voile sur Axion, un CPU sur base Arm Neoverse V2 conçu en interne et destiné à ses datacenters. Attendu de longue date, Google Axion devrait permettre des instances cloud 30% plus performantes que ce que propose actuellement le meilleur CPU Arm du marché. Le processeur, qui offrirait également un gain de 60% en terme d’efficacité énergétique par rapport aux CPU x86 de dernière génération, sera disponible d’ici la fin de l’année.

Google I/O en bref
En conclusion, la conférence Google I/O 2024 a été marquée par des avancées significatives dans le domaine de l’intelligence artificielle, en particulier avec Gemini 1.5 Pro et sa capacité à traiter de grandes quantités de données. L’intégration de Gemini dans la recherche Google et le système d’exploitation Android ouvre de nouvelles perspectives pour l’expérience utilisateur, bien que certaines questions subsistent quant à son activation et son impact sur les assistants existants.
Par ailleurs, Project Astra a démontré le potentiel d’un assistant multimodal basé sur Gemini, offrant des interactions plus intuitives et adaptées. Les annonces concernant Imagen 3, Music AI Sandbox et Veo témoignent également des progrès réalisés dans la génération d’images, de musique et de vidéos assistée par l’IA. Des avancées qui devraient avoir un impact significatif sur les futurs services et produits Google, tout en contribuant à façonner l’avenir de l’intelligence artificielle. A la rédaction, on se réjouit de toutes ces avancées qui devraient avoir rapidement des répercussions sur nos maisons connectées, notamment en rendant plus intelligente notre domotique. On attend maintenant avec impatience les annonces d’Amazon sur Alexa AI…
 Suivez-nous sur Google Actualités
Suivez-nous sur Google Actualités